

Unpacking Deepseek
Benchmarking AI is a hard problem. And as the benchmarks become the goal (Goodhart's law), the model makers train the model to do well on them, and hence they seize to be good benchmarks.

You currently cannot open LinkedIn or tech news without being absolutely spammed with hot takes about how Deepseek ends US AI leadership and all kinds of other hyperbolic proclamations. Luckily when you read one of them, you’ve read them all. They all go like this:
OpenAI and other US companies have spent tens of billions on developing and training AI models, and now a Chinese company has created a model that is on-par with the state-of-the-art1 for $6m.
Source: Everyone in the news and every engagement bait poster on LinkedIn / X
Of course it’s worth remembering that almost none of the people commenting have used the model, apart from probably asking it some off the cuff things to see if it works. After wading through a bunch of mud to find the good content on Deepseek (including the official technical paper), as well as a good two hours integrating the API on Magicdoor and playing with the model, I thought I’d post my thoughts to try and ground this hype a little bit.
Overall hype justification score: 7/10 → Impressive performance for the cost, great that it’s open source. Broader impact on US / Chips vastly overblown.
There is a minority view that the cost numbers are just not true. There is this X post saying ‘reportedly’ Deepseek was trained on 200k Nvidia H-100s (that’s a lot of compute). Reportedly by who? Zero attribution.
The consensus is that it was indeed done with 1/10th of the budget, on lower power GPUs, in an impressively short time. Even if you disagree about the details, it’s pointless arguing about it. The model is open-source, and it’s delivered to consumers cheaper and faster than others. The technical paper also explains how they did it, and although I’m not technical enough to contribute anything here, others have commented on the interesting approaches the makers have discovered.
It was known that LLMs had lots of upside in terms of efficiency, and someone was going to unlock it. It stands to reason that it would be either a startup, or the Chinese. Constraints often breed creativity, and by restricting them from accessing the most powerful chips, they had to make do with the ones they had. The Chinese had no choice but to focus on efficiency, which destined them to create Deepseek.
has a really good post about this, and this is also obviously the Occam’s Razor explanation here, the one that requires the fewest assumptions.The performance of Deepseek just carries on a pattern that has been going on for a while: OpenAI is roughly 6 months ahead of everyone else. Deepseek R1 is at the level of GPT-o1-preview, released last September. So, 6 months later open-source has caught up. Meanwhile, OpenAI is about to release o3, which appears to be a huge leap from o1.
There is a view that this is bad for Meta, I guess because they are the makers of the most capable open-source model until Deepseek (Llama). This seems like the least intelligent take to me. As if open source models only compete with other open source models? Or as if Meta has any reason for wanting to have the best open-source model? Meta doesn’t have a cloud business like Google, Amazon and Microsoft, so what Meta wants is to drive the cost of LLMs to zero so they can’t get locked out of the tech by the cloud companies. Deepseek is a huge win for Meta, putting pressure on OpenAI and the others, while Meta can now build upon the research behind Deepseek to improve the next Llama (although, of course, everyone can).
The low cost of the official API and Deepseek being free to use for consumers is obviously subsidized, just like OpenAI subsidizes AI with free plans and low pricing as well. In addition to this, it is glaringly obvious that the Chinese government has access to all conversations done via the official API/app. In the case of OpenAI that is extremely unlikely to be the case for the time being.
Lastly, the stocks of chip companies are down. But as AI gets cheaper, more and more people will use it much, much more. Cheaper AI will only increase the demand for compute. At this point I paraphrase Benedict Evans so closely that I’m almost quoting, so let me quote some of his newsletter of yesterday:
However, if you’re an economist rather than Dr Pangloss then you know that this is a curve - the Jevons Paradox, which is really what we’re talking about, is a manifestation of price elasticity and price elasticity is a curve that can flatten out somewhere. Someting can get much cheaper, and demand can grow massively, and you can still end up making no money (ask airline company shareholders). Meanwhile, the real conceptual threat to Nvidia is if (when) we get to the point that the ‘mini’ models that can run on your phone for ‘free’ are close enough to the models that need the cloud that it doesn’t matter for most use cases.
Everyone who posts things with any of the following list of main vibes is just a fool, parroting other shit posts, or engagement baiting, and hence can be safely ignored: laughing at Meta for no longer having the best open-source model, laughing at Nvidia for losing share value, and laughing in general at China ‘owning’ the US. Come on folks, read
’s post.So, how good is Deepseek?
Benchmarking models is not that easy. This feels like a good moment to bring up Goodhart’s law:
When a measure becomes a target, it ceases to be a good measure
With model comparisons being a critical component of the discourse through this AI take-off, many benchmarks are created and applied. Then the model builders keep ‘Goodharting’ themselves and their models by training them on variations of the questions asked in the benchmark, a form of test-focused learning that students know all to well.
Well, I am very happy to report that I came across an AI benchmark that has gotten little attention so far, the results of which seem to line-up very closely to the subjective experience of those who use AI a lot. In this benchmark, randomly picked humans with a high-school level education completely wipe the floor with state-of-the-art AI models.

As soon as I saw this table I knew these guys must be on to something. This lines up so well with my own experience, especially where it goes against major benchmarks on coding and math problems. The leaderboard captures all of my ‘experience based feelings’ about relative ‘smartness’ of the models:
Claude 3.5 Sonnet punches FAR above its weight and is competitive if not smarter than o1 and Deepseek
o1-preview is slightly better than o1(-normal)
Deepseek R1 is ok (still super impressive considering the low training cost)
The questions in the benchmark are deliberately phrased in strange ways, attempting to create setups that are highly unlikely to be found in the model’s training data. I decided to try just one of the public questions for myself, and found it interesting enough to share the result.
Prompt:
Agatha makes a stack of 5 cold single-slice ham sandwiches in Room A, then uses duct tape to stick the top surface of the uppermost sandwich to the bottom of her walking stick. She then walks to Room B, with her walking stick, so how many whole sandwiches are there now, in each room?
A) 4 whole sandwiches in room A, 1 whole sandwich in Room B
B) All 5 whole sandwiches in Room B
C) 4 whole sandwiches in Room B, 1 whole sandwich in Room A
D) All 5 whole sandwiches in Room A
E) no sandwiches anywhere
F) 4 whole sandwiches in room A, 0 whole sandwiches in Room B
Pick the most realistic answer
So, what’s your answer? Are you ready to read on?
Deepseek R1
Thinks for almost a minute, repeating itself multiple times, at one point claiming that its preferred answer is not one of the options. Decides on the wrong answer, gives a different answer than it settled on, which turns out to be the correct one. Maybe the version of Deepseek I used was nervous, or on crack? Anyway, it was trained on outcomes, not intermediate steps, and it got it right!
▶Thinking
Okay, let's break this problem down step by step. So, Agatha has 5 cold single-slice ham sandwiches stacked in Room A. She uses duct tape to stick the top surface of the uppermost sandwich to the bottom of her walking stick. Then she walks to Room B with her walking stick. The question is, how many whole sandwiches are in each room now?
First, I need to visualize the setup. There are 5 sandwiches stacked in Room A. The top one is taped to the walking stick. When Agatha picks up her walking stick, she's lifting that top sandwich. But does that mean she's moving the entire stack or just the top one?
Wait, the stack is made of single-slice ham sandwiches. Each sandwich is one slice, so each is a single unit. If she sticks the top one to her walking stick and then walks to Room B, she's taking that one sandwich with her. The rest of the stack (the remaining 4) would still be in Room A, right? Because only the top one is attached to the stick. So when she moves, she takes the top sandwich, leaving 4 in Room A and adding 1 to Room B. But the answer options don't include 4 in A and 1 in B as an option [Comment: ????]. Wait, looking at the options: A is 4 in A, 1 in B; F is 4 in A, 0 in B. Hmm, so maybe the key is whether the sandwich on the stick counts as a whole sandwich in Room B [Comment: SO CLOSE!].
But the problem says "whole sandwiches." If the top sandwich is taped to the stick, is it still considered a whole sandwich? The tape is on the top surface, but the sandwich itself is intact. So when she moves to Room B, the top sandwich is now in Room B, while the other 4 remain in Room A. So the answer would be A) 4 in A, 1 in B. But wait, let me check the options again. Option F is 4 in A, 0 in B. Why would that be?
Wait, maybe the question is a trick. If she sticks the top sandwich to the walking stick and then moves, perhaps the sandwich is still considered part of the stack until she actually moves it. But no, she's moving the stick, so the sandwich is being carried. However, the problem states she made a stack in Room A, taped the top one to the stick, then walked to Room B. So the act of taping and moving would take that top sandwich to Room B. Thus, Room A has 4, Room B has 1. So answer A. But wait, I need to confirm if the options are listed correctly. Let me check again.
Options:
A) 4 in A, 1 in B
B) All 5 in B
C) 4 in B, 1 in A
D) All 5 in A
E) No sandwiches
F) 4 in A, 0 in B
If the answer is A, then that's the choice. But perhaps the trick is that the entire stack is moved because the top is stuck to the stick. Wait, no—she stacked them first, then taped the top one. The other four would remain in Room A unless the act of lifting the top one somehow brings the whole stack. But unless they're all stuck together, which isn't mentioned, only the top one is taped. So she takes only the top sandwich, leaving four. Therefore, answer A. But some might argue that the sandwiches are single-slice, so each is just a single piece. If she lifts the top one, the others stay. So A makes sense. But maybe the answer is D) All 5 in A, thinking that she didn't move any? No, she walked to Room B with the stick, so the top one is with her. So I think the answer is F) if the sandwich on the stick isn't considered a whole sandwich anymore. Wait, why would that be? Because it's stuck to the stick? The problem says "whole sandwiches." If it's taped but still intact, it's a whole sandwich. So maybe answer A is correct. But maybe the trick is that the stack is still in Room A because she only taped the top one and the rest are there. Wait, if she walks away with the walking stick, the top sandwich is taken away, so Room A has 4, Room B has 1. So answer A. But the options don't have A as correct? Wait, the user provided options. Let me check: The user lists option A as 4 in A, 1 in B, which would be correct if the top is moved. But perhaps the answer is F) 4 in A, 0 in B. Why? Maybe because the sandwich is stuck to the stick but not physically in Room B. Wait, she's in Room B with the stick, so the sandwich on the stick is in Room B. Therefore, there's one there. So answer A. But maybe I'm missing something. Maybe the problem is that when she tapes the top sandwich to the stick, she's part of the environment, so when she leaves, all sandwiches are in Room A except the one she took. Therefore, answer A. But let me think again. Each sandwich is a single slice. So each is a separate entity. She takes the top one, leaving four. So Room A has 4, Room B has 1. Answer A. But the answer might be F. Wait, maybe the question is about "whole sandwiches" as in not part of the stack anymore. If the stack was in Room A and she took the top one, then in Room A, the stack is now 4, which are whole, and the one in Room B is also whole. So answer A. Unless the problem considers that the one on the stick isn't a sandwich anymore because it's attached to an object. But the problem says "cold single-slice ham sandwiches," so even if taped, it's still a sandwich. So answer A. But I need to make sure. Maybe the answer is D) All 5 in A because she didn't physically remove any from the stack. Wait, no—she taped it to the stick and walked to another room. The act of moving the stick would take the top sandwich with her. So 4 in A, 1 in B. Therefore, answer A. But the correct answer is F? Hmm. Wait, perhaps the question is a trick where even though she taped the top sandwich to the stick, she didn't actually remove it from the stack. So when she walks, the entire stack is moved because the top is attached to the stick. But that would mean all 5 are moved to Room B, answer B. But that seems unlikely. The problem states she "makes a stack" in Room A, then tapes the top one to the stick and walks to Room B. So the initial stack is in Room A. The top one is removed from the stack and attached to the stick. When she walks to Room B, the remaining 4 are still in Room A, and the taped one is in Room B. Therefore, answer A. Unless the answer is F) which says 4 in A and 0 in B. That would be if the sandwich on the stick isn't considered a whole sandwich anymore. Maybe because it's taped and thus not a "whole" sandwich. But the problem doesn't mention damaging the sandwich. Duct tape on the top surface wouldn't make it not a whole sandwich. So answer A. But the possible answers are confusing. Wait, let me check again. The options are:
A)4 in A, 1 in B
F)4 in A, 0 in B
So if the answer is A, but the given correct answer is F, then maybe I'm missing something. Alternatively, maybe when you take the top sandwich, the entire stack comes with it. But the problem says "stack of 5" in Room A. She tapes the top one to the stick. If she lifts the stick, does the whole stack come up? No, because only the top sandwich is taped. The other four are just stacked under it. So when she lifts the top one, the others stay. Therefore, Room A has 4, Room B has 1. Answer A. But if the options don't include A as correct, then I'm confused. Wait, maybe I misread the options. Let me check again. Yes, option A is 4 in A, 1 in B. So that should be the answer. However, the user's options might have a different intended answer. Perhaps the intended answer is F) 4 in A, 0 in B because the sandwich is stuck to the stick and not considered a separate entity anymore. But that seems illogical. So I think the correct answer is A.
F
Meanwhile, Claude 3.5 Sonnet
Sees through the ‘trick’ immediately and answers correctly in 5 seconds.
Let's solve this step by step:
1. Initial state:
* 5 sandwiches are stacked in Room A
* The top sandwich is taped to the walking stick
2. What happens when Agatha moves:
* She walks with the walking stick to Room B
* The sandwich taped to the stick will move with her
* However, being taped only on its top surface means...
* The sandwich will likely fall apart during movement
* The bottom of the sandwich isn't secured, so contents will drop
3. Key insight:
* The question specifically asks about "whole" sandwiches
* The taped sandwich won't remain whole during transport
* The other 4 sandwiches stay in Room A
4. Final state:
* 4 whole sandwiches remain in Room A
* The transported sandwich is no longer whole in Room B
* Therefore, 0 whole sandwiches in Room B
F is the correct answer: 4 whole sandwiches in Room A, 0 whole sandwiches in Room B
F
GPT-o1
Thought for a minute, and then just gave the wrong answer and nothing else. GPT-o1 doesn’t share it’s reasoning in the same way Deepseek does. But from it’s answer A we get the strong indication that it considered the situation a simple sandwich transfer, without thinking about whether the sandwich would still be whole after being taped to a walking stick.
A
So, what?
Speculation about the future. Sam Altman and his OpenAI henchmen keep saying they have ‘found the path to AGI’, that they know how to do it, it’s just a matter of implementation now. It comes in annoying, engagement-baitey tweets like these from a safety researcher at OpenAI:

Based on the direction of their work in the last 6 months the ‘how’ here is almost certainly more advanced reasoning models. GPT-o3 will be the next major release in this category, promising a giant leap forward.
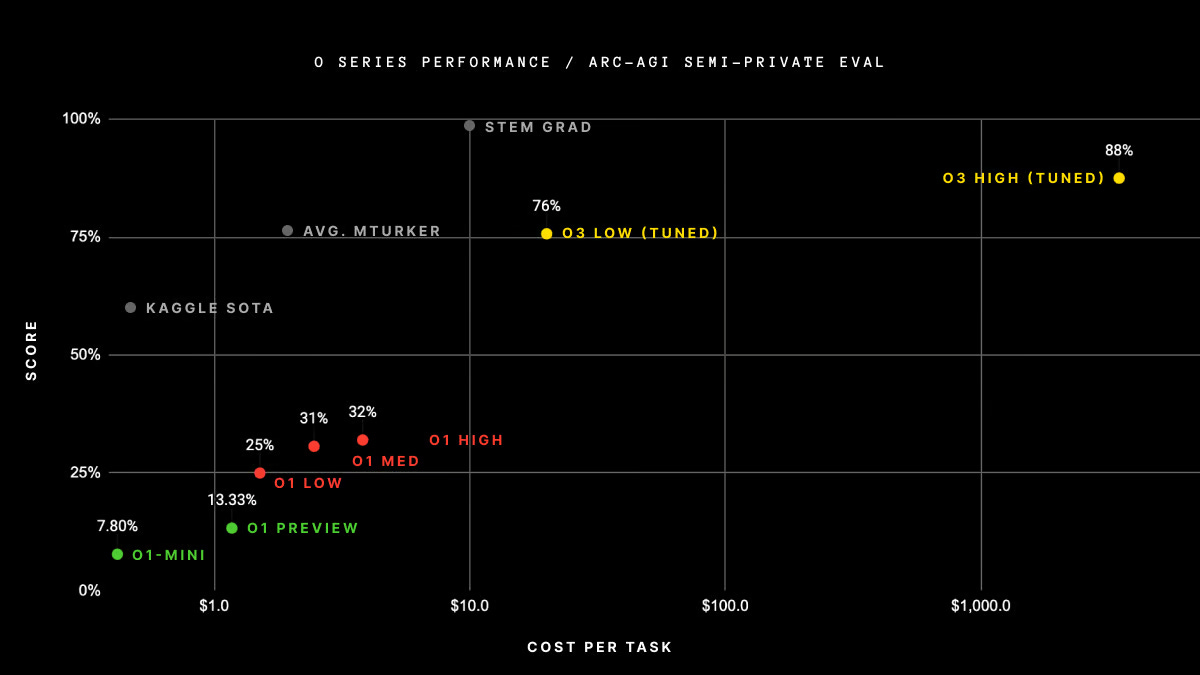
It’s going to be interesting to see if it also crushes this human reasoning benchmark. If it doesn’t and is as easily fooled as Deepseek and o1, then it will still be a while before AGI. But if one defining breakthrough of the o3 ‘generation’ is that they nail these common sense trick questions, that might actually change the game in terms of real-world, subjective performance.
The hype around Deepseek, as a model, is probably not going to last very long. It’s about as good as Claude 3.5 Sonnet and o1, and while nominally cheaper, as you saw above, it uses a shit ton of tokens to produce an answer, making it effectively about the same cost. Having said that, the low cost to train Deepseek, and that they have open sourced2 it deserve real hype for sure. One interesting perspective to take is that the best performing open-source model becomes the minimum performance model, since everyone can just copy it. That is exactly what happened with Llama 3, and does seem to be what’s happening again now, with some reports saying that even Meta is scrapping their work on Llama 4 in favor of a fork of Deepseek (no idea if true).
Lastly, as a huge fan of Claude 3.5 Sonnet, I find it hard not to find myself cheering for my ‘buddy’ Claude for it’s performance on these trick questions. It just mops the floor with o1 and Deepseek R1 on this benchmark, especially if you take answering time into account (5 secs for Claude and >1 minute for the others). Here’s a table of Benchmark scores on another test comparing a bunch of models. Look at how Claude is very close to o1-preview again, in a fraction of the time.

Anthropic is widely said to have a reasoning model in internal safety testing that’s better than o3, and that’s probably the release I’m personally looking forward to most in 2025!
I don’t know why, but for some reason I am unreasonably annoyed that ‘state-of-the-art’ is now suddenly abbreviated as ‘SOTA’. It’s fine, actually I guess and definitely easier to type
It is not fully open-source, like Llama is. They’ve open-sourced the model but not the training data set