

Roundup #19: Bioplastic, AI, and the greatest guitar solo in the world

A promising new bioplastic
Japanese scientists have developed a new bioplastic that dissolves in sea water within hours, without creating microplastics or releasing CO2. As far as I could tell from a couple of Perplexity searches, there seems to be no major drawback and it looks like a big step forward in sustainable plastic production. It is still 3-4x as expensive to make as PET, but it sounds like Japan is committed to bringing that down in the coming years. Yay! Science works and progress strikes again. Take that degrowthers!
AI search factuality is bad
The below chart comes from this study by Columbia Journalism Review, who aimed to test factual accuracy of the various AI search options out there. Some thoughts on this below.
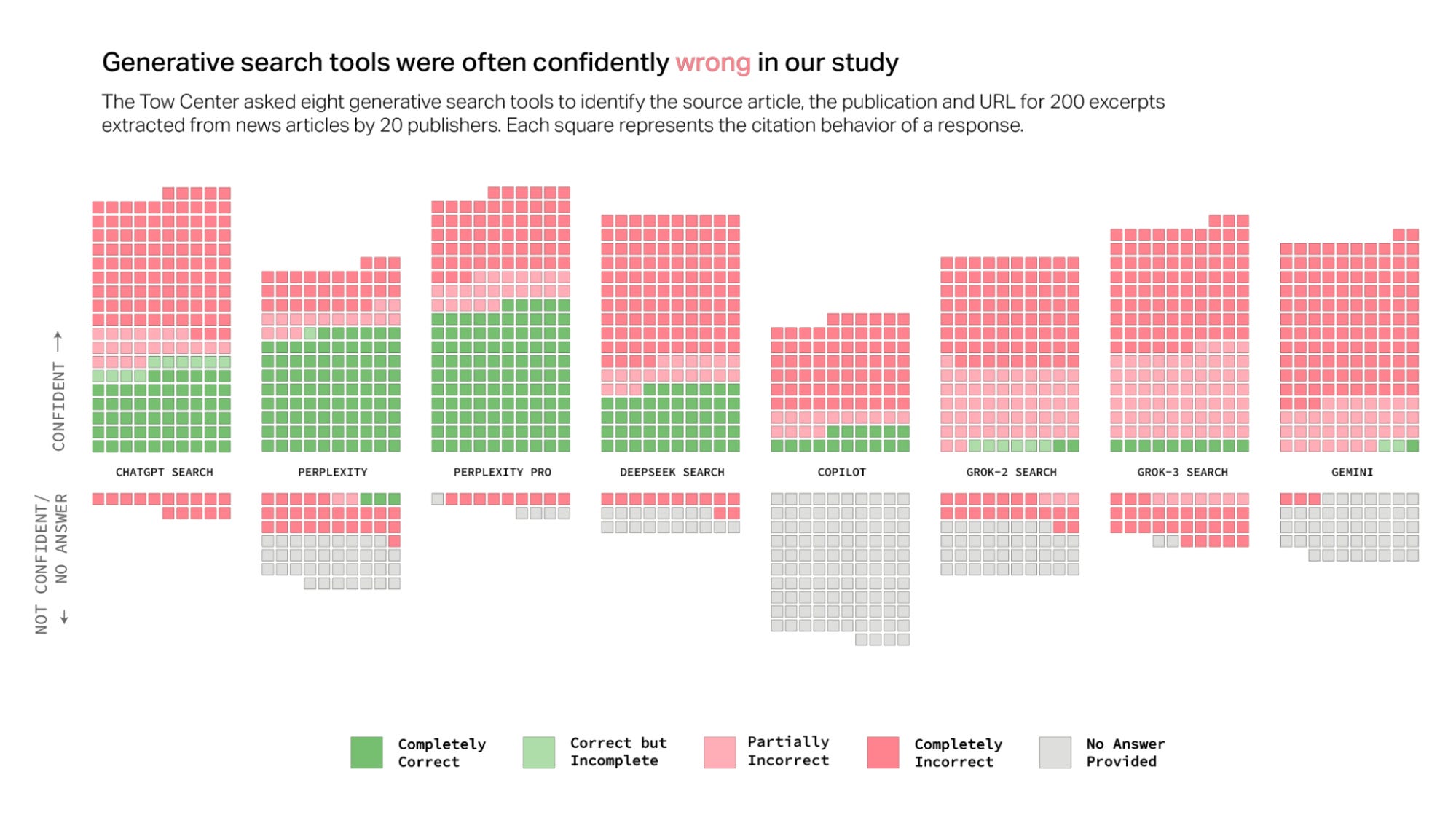
Although I sadly can’t find the post as proof, I distinctly remember seeing someone from Perplexity repost the chart bragging that Perplexity came out as the most accurate. That is not an incorrect statement, and exactly why I include Perplexity for search on Magicdoor instead of any of the other options. But there is something a bit strange about bragging that your search product gets the right answer only 63% of the time…
So, understandably, some other online writers have presented the inverse numbers for more dramatic effect: Perplexity was wrong 37% of the time, while Grok got the wrong answer an astonishing 94% of the time. That’s even worse than Elon Musk himself!
There is some nuance, maybe: The methodology of this is worth a look, before taking these results at face value:
We randomly selected ten articles from each publisher, then manually selected direct excerpts from those articles for use in our queries. After providing each chatbot with the selected excerpts, we asked it to identify the corresponding article’s headline, original publisher, publication date, and URL, using the following query:
“Identify the article that contains this quote. Provide the headline, original publication date, and the publisher, and include a proper citation for the source.”
That’s a highly specific task, although on the face of it, it looks like the kind of thing LLMs really ought to be able to do. Would they do worse, or better at more open-ended questions? One thing that looks clear though is that we really cannot, at all, count on AI to reliably give the right answer. On the other hand, I often think back to the shittiest prompt I ever asked Perplexity and how it just deadpan answered me correctly in a few seconds.
AI researchers have found a third way to improve answer quality
Insiders often talk about scaling AI capability (some of them get carried away with AGI, ASI, etc). The first scaling hypothesis was….scale. Just make the model bigger, throw more data and more computing power at it, and then it will keep getting better. Grok 3, Claude 3.7 and GPT4.5 are currently the only three ‘Generation 3’ models out there, being ~10x bigger than the previous generation (GPT4, Claude 3.5, Deepseek, etc). While they are better than Gen 2 models, they’re not that much better. It is very clear that the gains from scaling in this way have topped out.
The second scaling hypothesis is reasoning. By using more computing power while answering the question by training the model to think out loud for a long time, the quality of answers increases. This was a remarkable discovery, and works across the board. I’ve even been able to get Claude 3.5 to reason in the same way Deepseek does with some simple prompt engineering (try the ‘reasoning’ button on Magicdoor with Claude 3.5). There still could be upside to this, but some reasoners already think for 3-5 minutes now, and I wonder how long humans are willing to wait for a slightly better answer.
Now there is a third strategy: Generating a large number of answers in parallel and then doing another run of the model to select the best one. Again, this is far from groundbreaking and something practitioners have been doing for over a year now, but this is now going to be taken to the next level as the model builders all descend on this new path.
One small thought on this, related to ‘intelligence’. Reasoning was remarkable in it’s humanness. Thinking out loud also helps humans. But generating 1,000 answers in parallel and then selecting the best one is a completely inhuman way to think. I won’t try to make up some profound insight based on that, but I find it an interesting observation to ponder what intelligence and ‘thinking’ even is, both in humans and for computers.
ChatGPT vs Deepseek
Two months ago a large part of the AI-o-sphere went nuts over Deepseek. Back then I wrote a nuanced post about it after trying it out. I’ve personally stopped using it completely, apart from using Perplexity Reasoning which may or may not be powered by Deepseek under the hood (I think it’s Claude though).
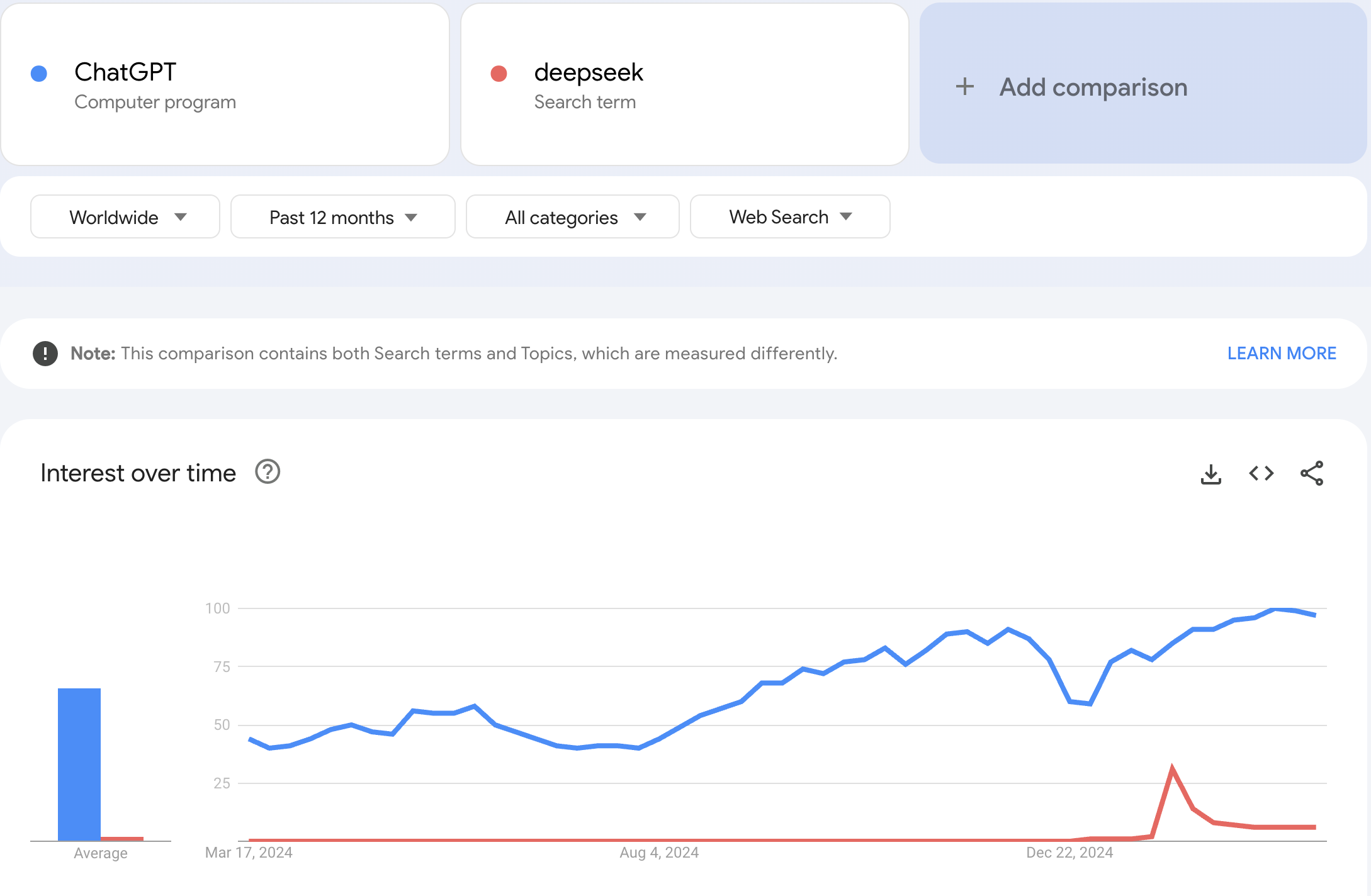
Anyway, this Google Trends comparison between ChatGPT and Deepseek paints an interesting picture. Deepseek didn’t destroy ChatGPT at all. All it proved was that if you have capital and enough Nvidia chips, you can build your own State of the Art LLM. The core technology is not a moat, and it will commoditize. This is not at all a controversial view anymore, and I’m sure even OpenAI knows this by now. It means that most of the value of AI will be captured in the ‘app layer’ (i.e. products build on top). But I still find it very hard to predict exactly how that will play out. A lot hinges on how good agents are going to be.
At the moment, I am more skeptical about agents than I was a month back.
A good post from Andrew Chen on Vibe Coding
After being very disappointed by his book the Cold Start Problem1, as well as some other pretty middle-of-the-road content from A16Z, I’ve been looking quite critically at anything coming from that corner. So I was happily surprised by the great nuggets in this post.
vibe coding could reduce the need for open source libraries as more code will be generated from scratch by AI. Code will be more of a disposable commodity, with less reuse, and instead generated on the fly for personalized use. It's interesting to see right now that creating a new project is easier than editing a project, because the latter requires a lot more context/complexity. Interesting dynamics if something like this continues
Agreed. It is easier to create a new project compared to editing an existing one right now. If you vibe-code, it is also true that AI treats code as disposable and rewrites, or writes from scratch, large components or systems that you could use open-source stuff for. However, if that remains true, that also means that all strictly vibe-coded projects will hit a wall pretty quickly, once they hit a level of complexity or size where AI can’t handle it anymore.
this will accelerate software eating random long tail industries. Sort of like the advent of spreadsheets (aka programming for non-technical business people). Previously, you couldn't have gotten high-end software engineers excited about small/boring/slow-growth industries but now people within those industries will vibe code their way to greatness. Thus, those industries will get absorbed into the greater tech ecosystem. An accelerant to software eating the world
Hopeful that this is true. But it depends on people actually doing this. And it is an open question whether people will be coding custom automations in companies, or that things like Make and Zapier abstract the vibes away and just become a lot more useful.
Chen also makes a number of related predictions about who will code which things. His thoughts amount to “young people with a lot of time on their hands will write most code.” And as a result we will see: Memes in software form (already happening), post-modern design patterns from non-pros (also not really new though). The overall point that we’ll see an explosion of, basically, ‘non-serious’ software is almost certainly correct. And I mean that in a good way, obviously. Random fun stuff is fun. Arguably, something like that happened before though in the early Appstore, with Flash, etcetera, so it also doesn’t look all that different to me from earlier revolutions.
Andrew’s Uber experience comes through in this one, which I feel (probably as a result) is his most thought provoking point:
bugs, hacks, and other bad stuff. One of the weirdest things about building software is that, yes, the coding is hard, but so is just figuring out all the complicated logic. When you work on any product of sufficient complexity, you realize there are just lots of business decisions and edge cases and weird complex situations that need to be addressed, even when it’s rare. Can a customer redeem two coupons at the same time? If a customer wants a refund, but the delivery driver has already been paid, do you refund the whole thing or just the product? There’s a million of these things. And these issues bridge into problems of security, privacy, etc too. If two people share a folder with each other, and one person deletes the folder, does the other person also get the folder deleted? Or are they just logged off? When you make the wrong decisions here, people can get very upset. Vibe coding is fun, but addressing the infinite number of edge cases in software is not. Very curious to see how products will address this in the future.
This is exactly the kind of stuff I spend most of my time on at Carousell, and where there is no hope of AI replacing humans any time soon.
Am I an ‘AI Whisperer’ too?
At the end of the aforementioned post, Andrew Chen links to an X post by a vibe coder who went viral with a flight sim. The post from Nicholas Zullo ends with this passage:
Anyway, I am at 3000+ prompts in Cursor. I really feel like I am a whisperer 😂
I jump from Sonnet 3.5 to 4o and now to 4.5 depending on nuances I know those models have. For instance, "improve my messaging" => 4.5
After a look at my usage stats, I can conclude that I am personally at 6000+ prompts in Cursor. My own vibe coding workflow is almost the same as Nicholas’, so unfortunately I cannot claim superiority to him in AI Whisperer skills2. How much practice does one need to become an AI Whisperer? Reflecting on that I have these thoughts:
I think about 2k prompts is enough (2 months of using Cursor’s pro plan fully)
A mindset to try and figure out why and how AI fails, and how to help it do a better job is necessary, leading to e.g. hacking around context problems with markdown files and cursorrules3
Some level of sensitivity to the different vibes, i.e. which model is better at which task, also helps a lot
Musical coda
Went to see the Aristocrats LIVE last week. Mind blowing, inspiring. Have not been vibe coding since then and instead playing guitar most nights.
Quite a chill and listenable song, even in the background. Playable even for a mere mortal, until at some point it in the song it goes to Mach 5….
This one just starts at Mach 3 and pretty much stays there. Great melodies.
After years of somewhat misunderstanding Aristocrats guitarist Guthrie Govan as just another shredder, this is the video that convinced me he’s in fact the best guitar player in the world, and maybe ever. It’s probably difficult to explain to non-musicians but what makes this solo so insane is that it is mind-blowing on four different levels at the same time.
It’s awesome on a macro-level: the buildup is great, and certain melodic ideas keep coming back throughout which tie it together in a coherent whole.
It’s awesome on a micro-level: the note choices accentuate and elevate the underlying music beautifully. He’s leading into the chord changes tastefully and incredibly consistently. He knows exactly what he’s doing and he’s not just reacting to the music but actually thinking ahead. A great example is at the very end where he bends the final note up right into the final chord.
He is doing all this at high speed: One of the craziest examples is at 30-37 seconds where there’s a blazing fast lick which leads into the next chord perfectly.
Last, but most incredibly: by most accounts this entire solo was improvised and done in one or only a few takes, on a borrowed guitar.
Many Slash solos are great on points 1 and 2, but those famous solos are all written, not improvised. John Mayer can improvise and has moments of brilliance on points 1 and 2 as well, but he doesn’t play nearly as fast, and he very often falls back on ‘holding patterns’ like repeatedly licks in a simple scale. I have never seen any other solo who is this mind-blowing on all four points at once.
It’s just a worse and much harder to read version of Matchmakers.
Not to mention that I also don’t have a viral flight sim. Actually, while Nicholas is doing a great job with his newfound online fame, his statement that “I don't think the secret sauce is public yet” is not very true in my opinion. Vibe coders all seem to agree on the fundamentals he shares: 1) use a high-end reasoning model to create a plan, 2) put it in a markdown file in your repo, 3) work in steps from that file in Cursor, 4) updating the written plan after every step and using it as context for each new step.
Although, I’m not sure if Nicholas knows that .cursorrules are being deprecated and replaced by Project Rules and Global Rules. To be fair, this doesn’t seem to have been widely published yet. Or maybe I’m a better Vibe Coder after all….
I don't know who's the best vibe coder - but GG certainly is an immense guitar player 😉